Continuous Time Markov Chain Expected Rewards
A continuous-time Markov chain (CTMC) is a continuous stochastic process in which, for each state, the process will change state according to an exponential random variable and then move to a different state as specified by the probabilities of a stochastic matrix. An equivalent formulation describes the process as changing state according to the least value of a set of exponential random variables, one for each possible state it can move to, with the parameters determined by the current state.
An example of a CTMC with three states is as follows: the process makes a transition after the amount of time specified by the holding time—an exponential random variable , where i is its current state. Each random variable is independent and such that , and . When a transition is to be made, the process moves according to the jump chain, a discrete-time Markov chain with stochastic matrix:






Equivalently, by the property of competing exponentials, this CTMC changes state from state i according to the minimum of two random variables, which are independent and such that for where the parameters are given by the Q-matrix




Each non-diagonal entry can be computed as the probability that the jump chain moves from state i to state j, divided by the expected holding time of state i. The diagonal entries are chosen so that each row sums to 0.

A CTMC satisfies the Markov property, that its behavior depends only on its current state and not on its past behavior, due to the memorylessness of the exponential distribution and of discrete-time Markov chains.
Definition [edit]
Let be a probability space, let be a countable nonempty set, and let ( for "time"). Equip with the discrete metric, so that we can make sense of right continuity of functions . A continuous-time Markov chain is defined by:[1]





- for all distinct ,
- for all (Even if is infinite, this sum is a priori well defined (possibly equalling ) because each term appearing in the sum is nonnegative. A posteriori, we know the sum must also be finite (not equal to ), since we're assuming it's equal to and we've assumed is real valued. Some authors instead use a definition that's word-for-word the same except for a modified stipulation , and say is stable or totally stable to mean , i.e., every entry is real valued.)[2] [3] [4]









Note that the row sums of are 0: or more succinctly, . This situation contrasts with the situation for discrete-time Markov chains, where all row sums of the transition matrix equal unity.


Now, let such that is -measurable. There are three equivalent ways to define being Markov with initial distribution and rate matrix : via transition probabilities or via the jump chain and holding times.[5]





As a prelude to a transition-probability definition, we first motivate the definition of a regular rate matrix. We will use the transition rate matrix to specify the dynamics of the Markov chain by means of generating a collection of transition matrices on ( ), via the following theorem.


Theorem: Existence of solution to Kolmogorov backward equations. [6] —There exists such that for all the entry is differentiable and satisfies the Kolmogorov backward equations:
![{\displaystyle P\in ([0,1]^{S\times S})^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a82f931c3541d55301cd95ef1b29938cc3ca3fcc)



-
(0)
![{\displaystyle P(0)=([i=j])_{i,j\in S},~\forall t\in T~\forall i,j\in S~~(P(t)_{i,j})'=\sum _{k\in S}Q_{i,k}P(t)_{k,j}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ace2c0846752a1e61e9851669bca814ec29a257)
We say is regular to mean that we do have uniqueness for the above system, i.e., that there exists exactly one solution.[7] [8] We say is irregular to mean is not regular. If is finite, then there is exactly one solution, namely and hence is regular. Otherwise, is infinite, and there exist irregular transition rate matrices on .[a] If is regular, then for the unique solution , for each , will be a stochastic matrix.[6] We will assume is regular from the beginning of the following subsection up through the end of this section, even though it is conventional[10] [11] [12] to not include this assumption. (Note for the expert: thus we are not defining continuous-time Markov chains in general but only non-explosive continuous-time Markov chains.)


Transition-probability definition [edit]
Let be the (unique) solution of the system (0). (Uniqueness guaranteed by our assumption that is regular.) We say is Markov with initial distribution and rate matrix to mean: for any nonnegative integer , for all such that for all




-
.[10]
(1)

Using induction and the fact that we can show the equivalence of the above statement containing (1) and the following statement: for all and for any nonnegative integer , for all such that for all such that (it follows that ),





-
(2)

It follows from continuity of the functions ( ) that the trajectory is almost surely right continuous (with respect to the discrete metric on ): there exists a -null set such that .[13]




Jump-chain/holding-time definition [edit]
Sequences associated to a right-continuous function [edit]
Let be right continuous (when we equip with the discrete metric). Define


let

be the holding-time sequence associated to , choose and let



be "the state sequence" associated to .
Definition of the jump matrix Π [edit]
The jump matrix , alternatively written if we wish to emphasize the dependence on , is the matrix


![{\displaystyle \Pi =([i=j])_{i\in Z,j\in S}\cup \bigcup _{i\in S\setminus Z}(\{((i,j),(-Q_{i,i})^{-1}Q_{i,j}):j\in S\setminus \{i\}\}\cup \{((i,i),0)\}),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0e4a6414ce439dbc15d5fa0346aee199cb94452)
where is the zero set of the function [14]


Jump-chain/holding-time property [edit]
We say is Markov with initial distribution and rate matrix to mean: the trajectories of are almost surely right continuous, let be a modification of to have (everywhere) right-continuous trajectories, almost surely (note to experts: this condition says is non-explosive), the state sequence is a discrete-time Markov chain with initial distribution (jump-chain property) and transition matrix and (holding-time property).




Infinitesimal definition [edit]
![]()
The continuous time Markov chain is characterized by the transition rates, the derivatives with respect to time of the transition probabilities between states i and j.
We say is Markov with initial distribution and rate matrix to mean: for all and for all , for all and for small strictly positive values of , the following holds for all such that :





- ,
![{\displaystyle \Pr(X(t+h)=j\mid X(t)=i)=[i=j]+Q_{i,j}h+o(h)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6af7e248408d8d248a87c40aa79c7aaa6bbac28)
where the little-o term depends in a certain way on .[15] [16]


The above equation shows that can be seen as measuring how quickly the transition from to happens for , and how quickly the transition away from happens for .




Properties [edit]
Communicating classes [edit]
Communicating classes, transience, recurrence and positive and null recurrence are defined identically as for discrete-time Markov chains.
Transient behaviour [edit]
Write P(t) for the matrix with entries p ij = P(X t =j |X 0 =i). Then the matrix P(t) satisfies the forward equation, a first-order differential equation

where the prime denotes differentiation with respect to t. The solution to this equation is given by a matrix exponential

In a simple case such as a CTMC on the state space {1,2}. The general Q matrix for such a process is the following 2 × 2 matrix with α,β > 0

The above relation for forward matrix can be solved explicitly in this case to give

However, direct solutions are complicated to compute for larger matrices. The fact that Q is the generator for a semigroup of matrices

is used.
Stationary distribution [edit]
The stationary distribution for an irreducible recurrent CTMC is the probability distribution to which the process converges for large values of t. Observe that for the two-state process considered earlier with P(t) given by
as t → ∞ the distribution tends to

Observe that each row has the same distribution as this does not depend on starting state. The row vector π may be found by solving[17]

with the additional constraint that

Example 1 [edit]
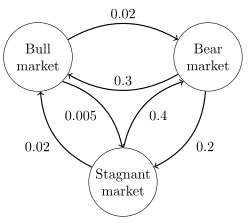
Directed graph representation of a continuous-time Markov chain describing the state of financial markets (note: numbers are made-up).
The image to the right describes a continuous-time Markov chain with state-space {Bull market, Bear market, Stagnant market} and transition rate matrix

The stationary distribution of this chain can be found by solving , subject to the constraint that elements must sum to 1 to obtain


Example 2 [edit]
![]()
Transition graph with transition probabilities, exemplary for the states 1, 5, 6 and 8. There is a bidirectional secret passage between states 2 and 8.
The image to the right describes a discrete-time Markov chain modeling Pac-Man with state-space {1,2,3,4,5,6,7,8,9}. The player controls Pac-Man through a maze, eating pac-dots. Meanwhile, he is being hunted by ghosts. For convenience, the maze shall be a small 3x3-grid and the monsters move randomly in horizontal and vertical directions. A secret passageway between states 2 and 8 can be used in both directions. Entries with probability zero are removed in the following transition rate matrix:

This Markov chain is irreducible, because the ghosts can fly from every state to every state in a finite amount of time. Due to the secret passageway, the Markov chain is also aperiodic, because the monsters can move from any state to any state both in an even and in an uneven number of state transitions. Therefore, a unique stationary distribution exists and can be found by solving , subject to the constraint that elements must sum to 1. The solution of this linear equation subject to the constraint is The central state and the border states 2 and 8 of the adjacent secret passageway are visited most and the corner states are visited least.

Time reversal [edit]
For a CTMC X t , the time-reversed process is defined to be . By Kelly's lemma this process has the same stationary distribution as the forward process.

A chain is said to be reversible if the reversed process is the same as the forward process. Kolmogorov's criterion states that the necessary and sufficient condition for a process to be reversible is that the product of transition rates around a closed loop must be the same in both directions.
Embedded Markov chain [edit]
One method of finding the stationary probability distribution, π, of an ergodic continuous-time Markov chain, Q, is by first finding its embedded Markov chain (EMC). Strictly speaking, the EMC is a regular discrete-time Markov chain. Each element of the one-step transition probability matrix of the EMC, S, is denoted by s ij , and represents the conditional probability of transitioning from state i into state j. These conditional probabilities may be found by

From this, S may be written as

where I is the identity matrix and diag(Q) is the diagonal matrix formed by selecting the main diagonal from the matrix Q and setting all other elements to zero.
To find the stationary probability distribution vector, we must next find such that


with being a row vector, such that all elements in are greater than 0 and = 1. From this, π may be found as


(S may be periodic, even if Q is not. Once π is found, it must be normalized to a unit vector.)
Another discrete-time process that may be derived from a continuous-time Markov chain is a δ-skeleton—the (discrete-time) Markov chain formed by observing X(t) at intervals of δ units of time. The random variables X(0),X(δ),X(2δ), ... give the sequence of states visited by the δ-skeleton.
See also [edit]
- Kolmogorov equations (Markov jump process)
Notes [edit]
- ^ Ross, S.M. (2010). Introduction to Probability Models (10 ed.). Elsevier. ISBN978-0-12-375686-2.
- ^ Anderson 1991, See definition on page 64.
- ^ Chen & Mao 2021, Definition 2.2.
- ^ Chen 2004, Definition 0.1(4).
- ^ Norris 1997, Theorem 2.8.4 and Theorem 2.8.2(b).
- ^ a b Anderson 1991, Theorem 2.2.2(1), page 70.
- ^ Anderson 1991, Definition on page 81.
- ^ Chen 2004, page 2.
- ^ Anderson 1991, page 20.
- ^ a b Suhov & Kelbert 2008, Definition 2.6.3.
- ^ Chen & Mao 2021, Definition 2.1.
- ^ Chen 2004, Definition 0.1.
- ^ Chen & Mao 2021, page 56, just below Definition 2.2.
- ^ Norris 1997, page 87.
- ^ Suhov & Kelbert 2008, Theorem 2.6.6.
- ^ Norris 1997, Theorem 2.8.2(c).
- ^ Norris, J. R. (1997). "Continuous-time Markov chains II". Markov Chains. pp. 108–127. doi:10.1017/CBO9780511810633.005. ISBN9780511810633.
References [edit]
- Anderson, William J. (1991). Continuous-time Markov chains: an applications-oriented approach. Springer.
- Leo Breiman (1992) [1968] Probability. Original edition published by Addison-Wesley; reprinted by Society for Industrial and Applied Mathematics ISBN 0-89871-296-3. (See Chapter 7)
- Chen, Mu-Fa (2004). From Markov chains to non-equilibrium particle systems (Second ed.). World Scientific.
- Chen, Mu-Fa; Mao, Yong-Hua (2021). Introduction to stochastic processes. World Scientific.
- J. L. Doob (1953) Stochastic Processes. New York: John Wiley and Sons ISBN 0-471-52369-0.
- A. A. Markov (1971). "Extension of the limit theorems of probability theory to a sum of variables connected in a chain". reprinted in Appendix B of: R. Howard. Dynamic Probabilistic Systems, volume 1: Markov Chains. John Wiley and Sons.
- Markov, A. A. (2006). Translated by Link, David. "An Example of Statistical Investigation of the Text Eugene Onegin Concerning the Connection of Samples in Chains". Science in Context. 19 (4): 591–600. doi:10.1017/s0269889706001074.
- S. P. Meyn and R. L. Tweedie (1993) Markov Chains and Stochastic Stability. London: Springer-Verlag ISBN 0-387-19832-6. online: MCSS . Second edition to appear, Cambridge University Press, 2009.
- Kemeny, John G.; Hazleton Mirkil; J. Laurie Snell; Gerald L. Thompson (1959). Finite Mathematical Structures (1st ed.). Englewood Cliffs, NJ: Prentice-Hall, Inc. Library of Congress Card Catalog Number 59-12841. Classical text. cf Chapter 6 Finite Markov Chains pp. 384ff.
- John G. Kemeny & J. Laurie Snell (1960) Finite Markov Chains, D. van Nostrand Company ISBN 0-442-04328-7
- E. Nummelin. "General irreducible Markov chains and non-negative operators". Cambridge University Press, 1984, 2004. ISBN 0-521-60494-X
- Seneta, E. Non-negative matrices and Markov chains. 2nd rev. ed., 1981, XVI, 288 p., Softcover Springer Series in Statistics. (Originally published by Allen & Unwin Ltd., London, 1973) ISBN 978-0-387-29765-1
- Suhov, Yuri; Kelbert, Mark (2008). Markov chains: a primer in random processes and their applications. Cambridge University Press.
Source: https://en.wikipedia.org/wiki/Continuous-time_Markov_chain
0 Response to "Continuous Time Markov Chain Expected Rewards"
Post a Comment